website
Abstract
In this study, we investigate into the task of author attribution, specifically seeking to identify which South African president pronounced a particular statement in the State of Nations Adress. Various machine learning techniques were tested in the task of author attribution: from Naive Bayes Classifier and XGBoost, trained on both Bag-of-Words (BoW) and Term Frequency-Inverse Document Frequency (TF-IDF) representations, to the two and four-layered neural networks, and the state-of-the-art Bidirectional Encoder Representation Transformer (BERT) model an architecture found in popular large language models. Notably, the two-layered network showcased superior performance, defying our initial expectations. On a broader scale, however, the overall efficacy of our models in accurately attributing statements to presidents remained suboptimal. Key influencing factors identified include imbalanced data representation, particularly for presidents deKlerk and Motlanthe, lack of training datathe finiteness of sentence structure, and the lack of an exhaustive hyperparameter optimization. Despite these challenges, the study sheds light on the difficulties of authorship identification through machine learning and highlights the importance of data representation and model optimization.
Introduction
A State of Nation Address (SONA) is a speech given by the President of South Africa in which the president reports on the status of the nation. It functions as an annual report that include political and socio-economic topics. These include but not limited to topics surrounding the nation’s budget, economy, news, agenda, progress, achievements and the president’s priorities and legislative proposals. The SONA gives us an idea of broader political landscape and socio-economic issues and challenges that are plaguing the country. At the same time, it also reflect on the achievements and growth and progress the country has made in the past year. Consequently, the nuances in the content, style, and delivery of these addresses provide insightful glimpses into the leadership styles and priorities of different presidents. Thus, developing a machine learning model to figure out which president said a particular statement is avenue to assess the predictive power of these models in a Natural Language Processing task. In addition to this, it may provides insight in linguistic signatures of the various presidents and if they are distinct enough to be identified by a machine learning model.
In this assignment, we will be comparing the performance of different machine learning models in the task of authorship attribution. Author attribution is the task of identifying the author of a given text. More specifically, we will use the SONA speeches given by the presidents of South Africa from 1994-2022 and predict which president said which statement. In the assignment, we will test multiple machine learning models including Multinomial Naive Bayes Classifier, eXtreme gradient boosting (XGBoost), feed forward neural network and a Bidirectional Encoder Representations from Transformers (BERT) model. We opt on this selection of models due to the assignment requirements but also added in a transformer model due to the recent popularity explosion in large languague models (LLM) such as BART and chatGPT. In addition to this, we will also vary aspects of the training data by using various text mining and preprocessing techniques such as count vectorization, tf-idf vectorization, and training attention masks for the BERT model. By doing so, we aim to construct models capable of attributing specific sentences to their respective presidents and comparing the performance of those respective models.
A related study on authorship attribution using machine learning [@ramnial2016authorship]. The study compared a two machine learning models namely K-Nearest Neighbour, and Sequential minimal optimization to assign PhD thesis to their corresponding authors.
Moreover, there is a survey on different statistical and machine learning techniques for author attribution. The survey compares and contrasts different techniques to each other and also highlights important parameters such as length of corpus, number of candidate authors and distribution of training corpus over the authors (balanced or imbalanced) . All these factors will be considered for the current analyzes [@stamatatos2009survey].
Furthermore, with the recent popularity of LLM, transformer approaches recently been explored for authorship attribution. @fabien2020bertaa fine-tuned a pre-trained BERT for author classification. The BERT model performs the best when sufficient training data per author are available, there is no large class imbalance.
The relevant work showcases that researchers have found significant results when discerning which body of text belongs to which person using a variety of machine learning and deep learning techniques. The following study aims to take inspiration from all the mentioned related works to implement multiple deep learning and machine learning approaches to predict which South African president said which sentence as apart of the SONA speeches.
Data
The primary dataset utilized in this study comprises the textual transcripts of the State of the Nation Address (SONA) delivered by various South African presidents from the year 1994 to 2022. These transcripts were sourced from the official government website (https://www.gov.za/state-nation-address). The presidents represented in the SONA speeches are F.W deKlerk, Nelson Mandela, Thabo Mbeki, Jacob Zuma, K. Montlante and Cyril Ramaphosa.
For the purpose of the study, the dataset was divided into training, validation, and test sets with proportions of 70%, 10%, and 20% respectively.
Data Exploration
Figure 1 showcases the frequency of the top 15 words used by different presidents in their State of the Nation Addresses (SONA). The data is curated after removing common stop words to highlight words of significance and value in understanding each president’s primary focuses and concerns during their respective terms.
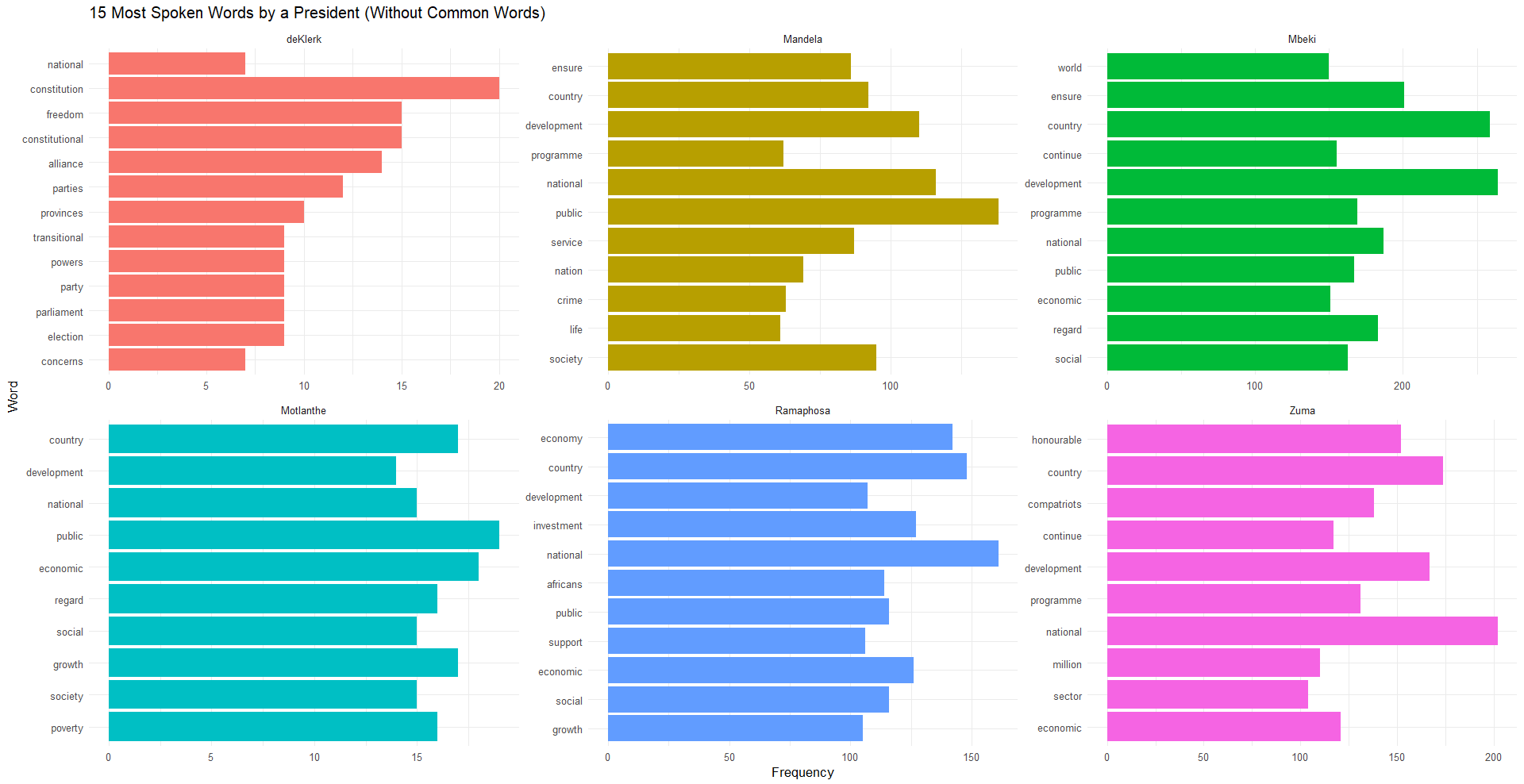
Data Imbalances
Data imbalance refers to a situation in classification tasks where the classes are not represented equally in the dataset. Data imbalance stands as a significant challenge in the context of our assignment as the presidents do not have equal representation in the datasets. This issue becomes evident when examining the distribution of sentences across different South African presidents. For instance, while De Klerk has a mere 97 sentences from one speech, other presidents like Mandela and Ramaphosa exceed 1000 sentences, and both Mbeki and Zuma surpass the 2000 mark. This stark disparity in data distribution can jeopardize the efficacy of our classifiers.
| Mandela | Mbeki | Motlanthe | Zuma | Ramaphosa | de Klerk | |
|---|---|---|---|---|---|---|
| No Sentences | 1668 | 2397 | 264 | 2629 | 2281 | 97 |
Data Cleaning
In the assignment, a vital preprocessing step involves cleaning the textual data. We implement functions to standardize and sanitize the text data by undergoing a series of transformations. Initially, the text is converted to lowercase to maintain uniformity. We then eliminate any text within square brackets and strip off URLs, ensuring that the content is free from external links or irrelevant metadata. HTML tags. Moreover, we’ve also incorporated the removal of commonly used words or ‘stop words’ that do not carry significant meaning in the context of text analytics. Furthermore, the text data undergoes stemming using the Snowball Stemmer, a process that trims words down to their base or root form, thereby ensuring different forms of a word are treated as one.
Preprocessing
In the study we will explore into two widely recognized text representation techniques: Bag of Words (BoW) and Term Frequency-Inverse Document Frequency (TFIDF). Preprocessing data using BoW and TFIDF is crucial for machine learning classification because it transforms textual data into numerical vectors, enabling algorithms to effectively identify patterns and relationships. While BoW emphasizes the frequency of words in a document, disregarding the order or structure, TFIDF goes a step further by weighing the terms based on their significance across a collection of documents.
We will compare both of the text representation techniques for the Naive Bayes, and XGBoost classifier in the task of identifying which president said which sentence.
Bag of Words/Count Vectorization
Bag of words is a technique used in natural language processing and text mining to convert text data into numerical format.
This process begins with tokenization, where the text is parsed into individual words or tokens. Following this, a vocabulary of distinct tokens is constructed, serving as a reference point for translating texts into vectors. When encoding text as a vector, the length corresponds to the vocabulary’s size, with each element indicating the frequency of a particular word in the text. For instance, given a vocabulary “apple”, “banana”, “cherry”, the text “apple banana apple” would be vectorized as [2,1,0].
Term Frequency-Inverse Document Frequency (TF-IDF)
Term Frequency-Inverse Document Frequency (TF-IDF) is a numerical statistic that reflects the importance of a word in a document relative to a collection or corpus of documents. It is widely used in the domain of information retrieval and text mining.
TF-IDF is composed of two components:
Term Frequency (TF): This quantifies how frequently a term appears in a document. It is calculated as: \[TF(t) = \frac{\text{Number of times term } t \text{ appears in a document}}{\text{Total number of terms in the document}}\]
Inverse Document Frequency (IDF): This measures the importance of a term. If a term is frequent across many documents, it may not be a unique identifier and may not be useful in distinguishing between documents. IDF is determined as: \[IDF(t) = \log\left(\frac{\text{Total number of documents}}{\text{Number of documents containing term } t}\right)\]
The product of TF and IDF gives the TF-IDF weight of a term in a document. A high TF-IDF score means the term is significant in the given document when compared to the corpus.
Attention Masks
Lastly, attention masks were used to train the BERT transformer model. Attention masks serves as a mechanism to control which parts of the input sequence the model should pay attention to during the training or inference process. This involves training the model by predicting the masked word in the sequence for all sequences to learn a representation of the language itself. We utilize these attention masks and the pretrained weights from the BERT uncased Base model and train it on the SONA data in hopes it learns representations to predict which president is associated with which sentence.
Models
Naive Bayes Classifier
Given a set of features \(\mathbf{x}\) and a target class \(C\), the Bayes theorem calculates the posterior probability \(P(C|\mathbf{x})\) as:
\[P(C|\mathbf{x}) = \frac{P(\mathbf{x}|C)P(C)}{P(\mathbf{x})}\]
Where:
\(P(C|\mathbf{x})\) is the posterior probability of class \(C\) given the features \(\mathbf{x}\).
\(P(\mathbf{x}|C)\) is the likelihood of features \(\mathbf{x}\) given class \(C\).
\(P(C)\) is the prior probability of class \(C\).
\(P(\mathbf{x})\) is the evidence, which acts as a normalization constant.
In the Naive Bayes classifier, the likelihood term \(P(\mathbf{x}|C)\) is computed by assuming feature independence and multiplying the individual likelihoods for each feature.
XGBoost
XGBoost stands for Extreme Gradient Boosting, and it’s a powerful and efficient implementation of the gradient boosting framework. It’s widely recognized for its performance and speed. XGBoost works by iteratively adding a set of weak learners (usually decision trees) to model the residual errors from previous iterations.
The core principle behind XGBoost is to correct the mistakes of the previous trees by focusing more on misclassified points (by assigning them higher weights). This process is achieved through a mathematical framework that involves the calculation of gradient and hessian (second-order gradient) for a given loss function.
Given a differentiable loss function \(l(y, \hat{y})\), where \(y\) is the true label and \(\hat{y}\) is the predicted label, the objective function \(\mathcal{L}\) to be optimized in each step can be represented as:
\[\mathcal{L} = \sum_{i=1}^{n} l(y_i, \hat{y}_i^{(t)}) + \Omega(f_t)\]
Where:
\(n\) is the number of data points.
\(\hat{y}_i^{(t)}\) is the prediction at the \(i^{th}\) iteration.
\(\Omega\) is the regularization term to prevent overfitting.
\(f_t\) is the model at the \(t^{th}\) iteration.
The regularization term, and its importance in controlling the complexity of individual trees, differentiates XGBoost from other gradient boosting algorithms.
In the assignment, we employed the XGBoost model for classification. The model was tuned with a learning rate of 0.1, a maximum depth of 7 for the trees, and an ensemble of 80 estimators. A grid search to search for the optimal hyperparameters can be conducted. However, this is elaborated in the limitations section.
Neural Networks
Neural networks are a type of deep learning algorithms used for pattern recognition and classification. A neural network is composed of layers of interconnected nodes called neurons. Data enters from the input layer, and as it traverses through the network’s hidden layers, each neuron processes the data, applying a weighted sum and a non-linear activation function. The final layer, known as the output layer, produces the prediction.
Mathematically, for a given neuron, its output \(y\) is a function of the weighted sum of its inputs \(x\) and its bias \(b\). The formula for a single neuron can be represented as:
\[y = f\left( \sum_{i} w_i x_i + b \right)\]
where:
\(w_i\) is the weight of the \(i^{th}\) input,
\(x_i\) is the \(i^{th}\) input,
\(b\) is the bias,
and \(f\) is the activation function, which introduces non-linearity, enabling the network to capture complex patterns.
Training a neural network involves adjusting the weights and biases using optimization techniques, such as gradient descent, to minimize the error between the predicted and actual outputs.
In the case of the assignment, a feedforward neural network is used, where connections between nodes do not form cycles or backpropogate, restricting information to flow in one direction, from input to output.
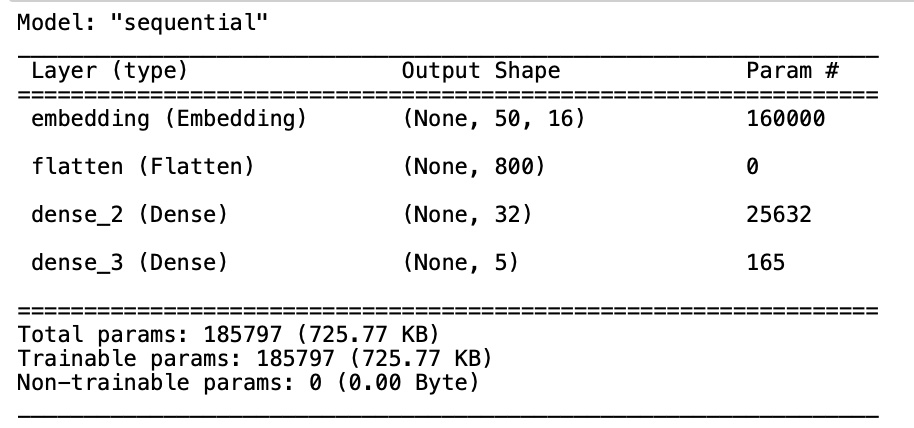
Two neural networks will be compared for this study. The first neural network has 2 layers, and the other neural network has 4 layers with two dropout layers for regularization. Figure 2 illustrates the neural network with two layers used. Moreover, Figure 3 The neural network used Both the neural networks were trained at 50 epoch.
Image for second neural network
Transformers
Transformers are a type of deep learning architecture introduced by researchers at Google in a 2017 paper titled “Attention is All You Need.” They have become foundational for a range of Natural Language Processing (NLP) tasks, including translation, summarization, and various other applications.
Unlike traditional recurrent or convolutional layers, Transformers use a self-attention mechanism to weigh input sequences that embed context.
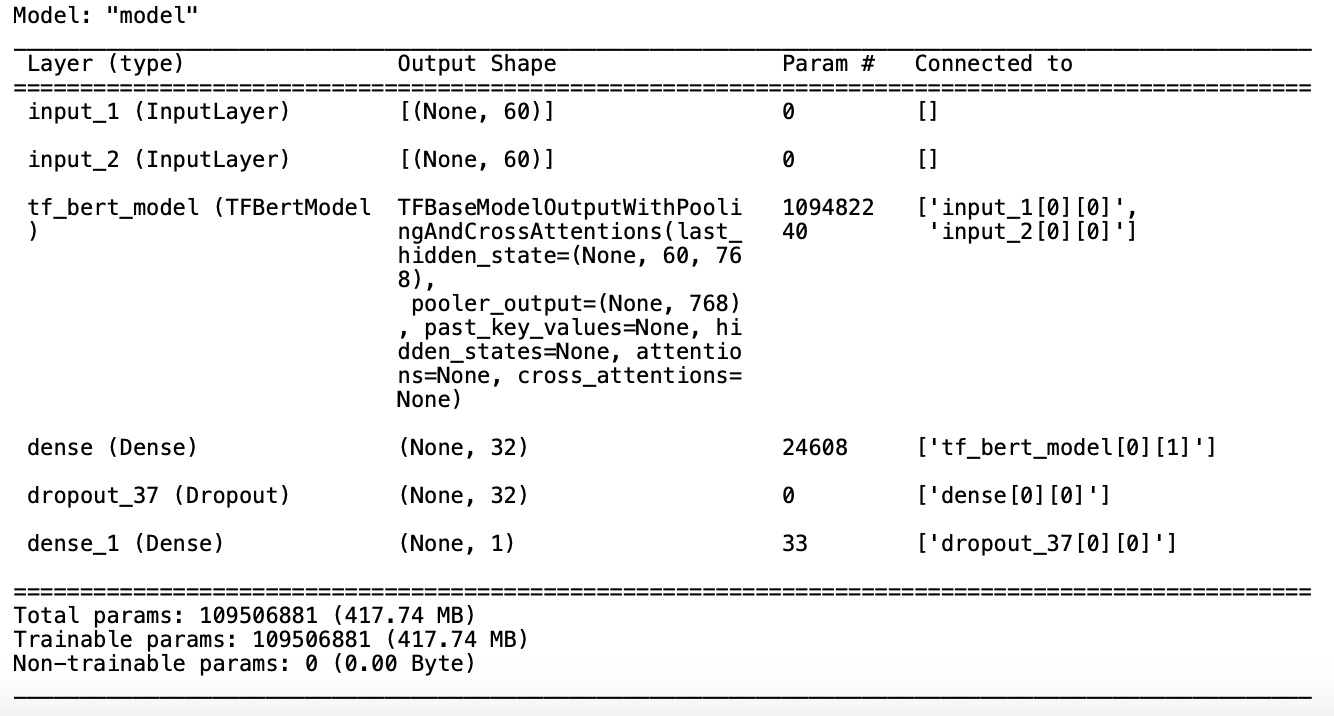
In the assignment, we will utilize a pre-trained Bidirectional Encoder Representations from Transformer (BERT) model and engage in a fine-tuning process to adapt it to our specific task, which is to predict which president uttered a given sentence. BERT is a deep learning model for natural language processing tasks, developed by Google. It reads text bidirectionally to understand the context better, which significantly enhances its performance on various NLP tasks.
Figure 3 demonstrates the model BERT architecture utilized in this assignment. The BERT model was pretrained on BookCorpus, a dataset consisting of 11,038 unpublished books and English Wikipedia. The Bert model ran for 3 epoch and used training attention masks as input.
Bidirectional Encoder Representation Transformer (BERT)
Results
Naive Bayes Classification (BoW)
speak about results for all classification
Naive Bayes Classification with TF-IDF
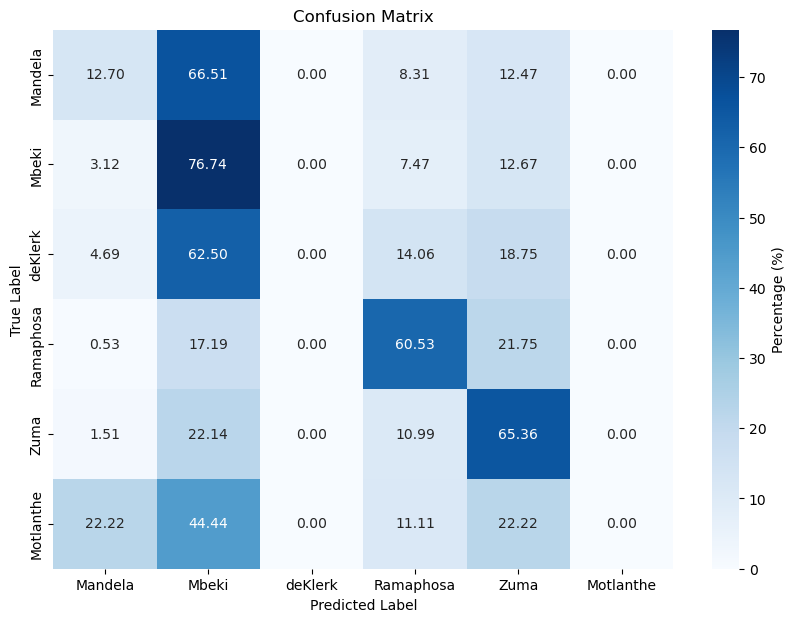
XGBoost (BoW)
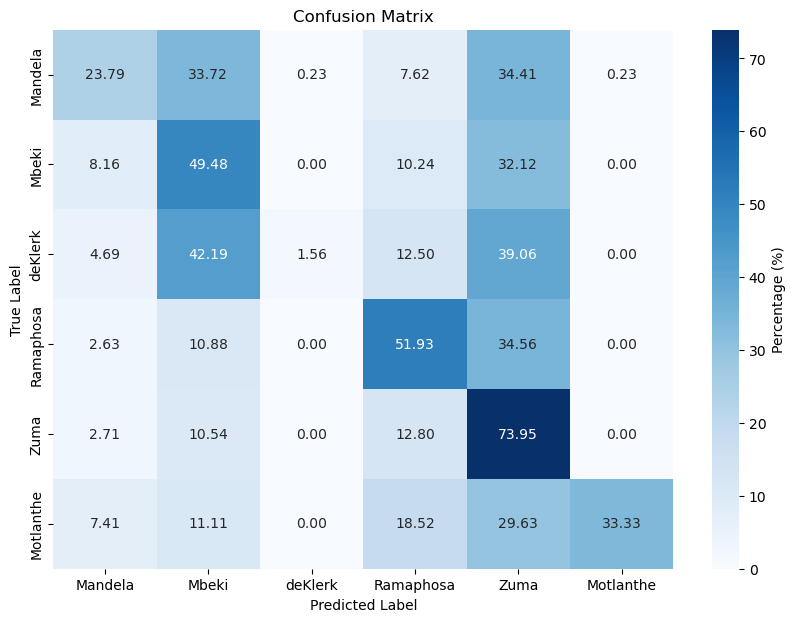
XGBoost with TF-IDF
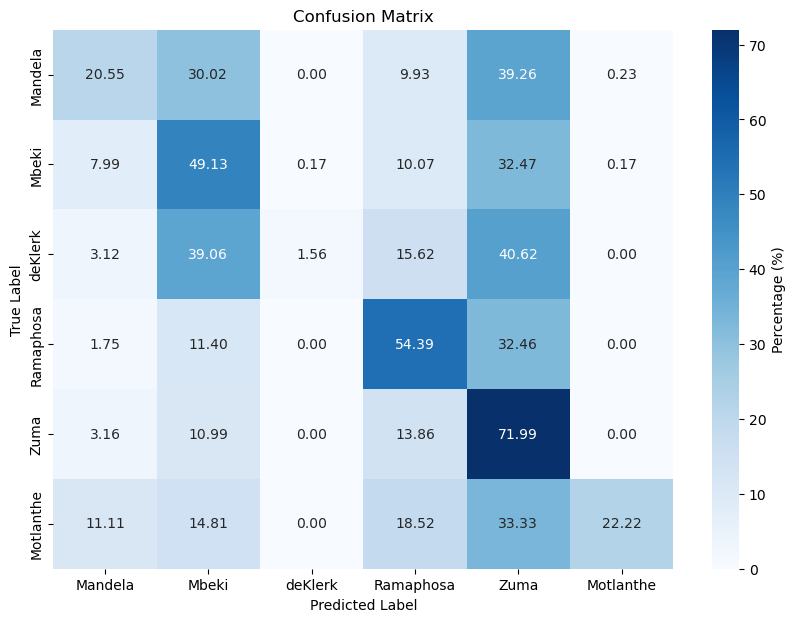
Feed Forward Neural Network
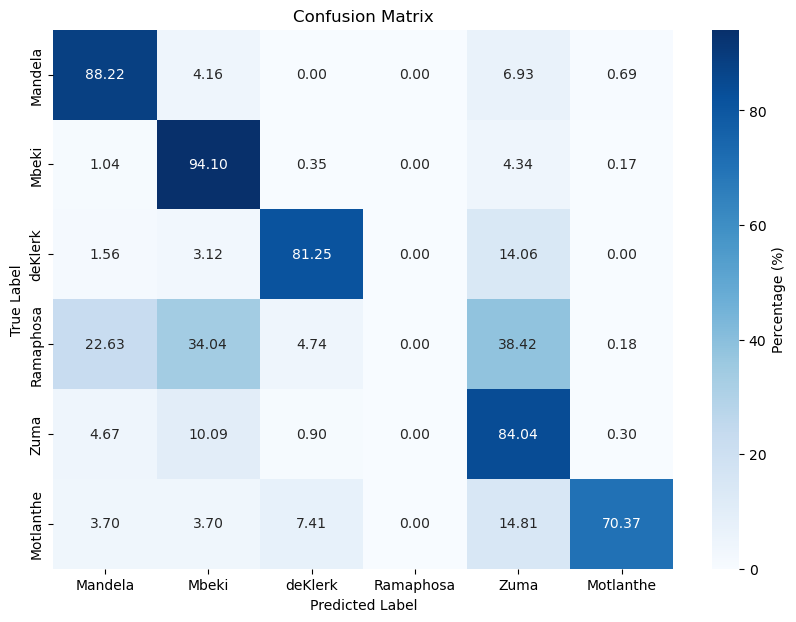 2-layered Neural Network
2-layered Neural Network

4-layered Neural Network
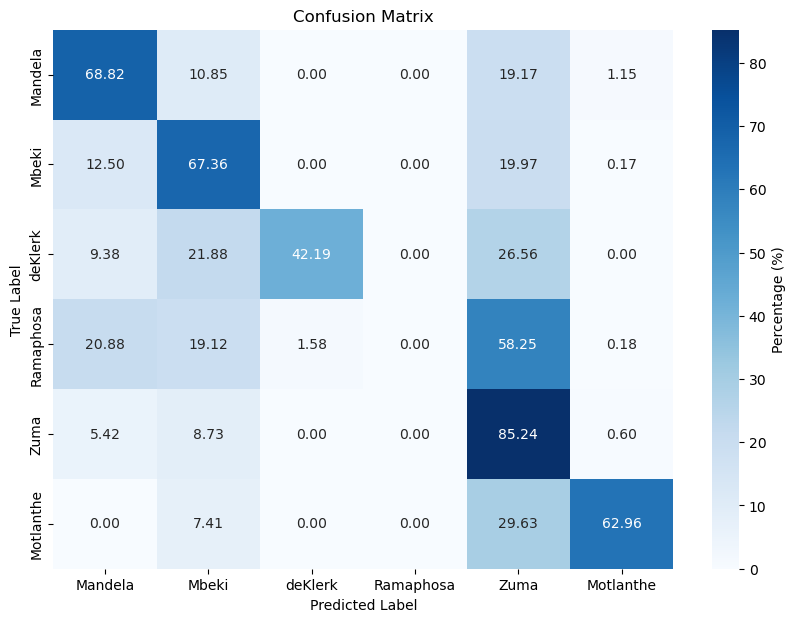
BERT (Transformer Language Model)
| Model | Training Accuracy | Test Accuracy |
|---|---|---|
| Naive Bayes Classifier BoW | 71.77 | 58.14 |
| Naive Bayes Classifier with TF-IDF | 71.76 | 54.67 |
| XGBoost (BoW) | 71.76 | 50.00 |
| XGBoost with TF-IDF | 71.77 | 50.77 |
| Feed Forward Neural Network (2 Layers) | 90.64 | 67.57 |
| Feed Forward Neural Network (4 Layers) | 66.17 | 56.51 |
| BERT | - | - |
Discussion and Conclusion
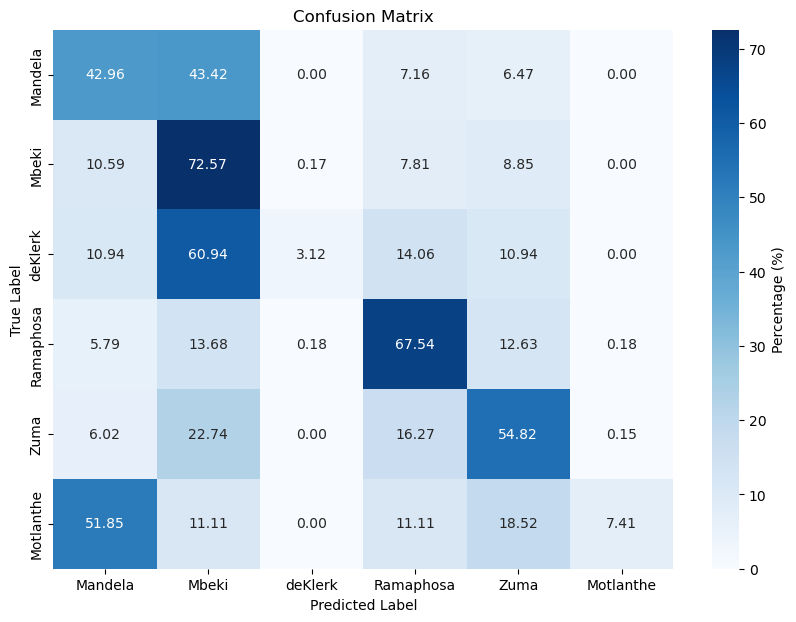
In our investigation, it is noteworthy to mention that the two-layered neural network outperformed its four-layered in both the training and testing datasets, Contrary to our initial anticipation. It’s possible that the four-layered network’s added complexity rendered it more prone to overfitting, This highlights the notion that a more intricate model isn’t neccasilary better in author attribution.
In addition to this, we did not obtain a good model for predicting which president said which sentence. It seems as if the models did not learn any representations for deKlerk or Motlanthe as they both have exteremely low accuracy scores accross the all models. This could have hampered the performance are the fact that the data is unbalanced. Given the fact that deKlerk and Mothlanthe were severely underrepresented in the data, this might have affected the models’ performative ability. To mitigate that an imbalanced dataset resampling methods such as Synthetic Minority Over-sampling Technique (SMOTE) where you create synthetic samples in the dataset for the underrepresented class. Resampling methods are typically beneficial for addressing class imbalances.
We believe that sentence structure is too finite to predict which sequence was said by which president. Therefore, we suffered from lack of performance. This means that it is harder for the models to discern which president said which sentences as the sentences were not long enough to extract linguistic properties that may be associated with a certain president.
Another important factor in the assignment is that a hyperparameter search or a grid search was not performed for any of the above model. This can serve as a possible way to extract a optimal model to predict which president said what statement.
In summary, while the assignment furnishes valuable insights into the potential and pitfalls of utilizing machine learning for author classification, it also highlights the importance of data quality, balance, and comprehensive model optimization. Future works in this domain would benefit from addressing these challenges.